教師あり学習とは?初心者にも分かりやすく解説!
「教師あり学習」という言葉を耳にしたことはありますか?AIや機械学習の世界では、欠かせない学習方法の一つです。しかし、「一体どんなもの?」「何ができるの?」と疑問に思っている方も多いのではないでしょうか。 本記事では、教師あり学習の基礎知識を初心者にも分かりやすく解説します。定義や仕組み、メリット・デメリット、具体的な活用事例を理解し、あなたもAIの世界へ足を踏み入れましょう!
Contents
教師あり学習とは?
AIや機械学習の世界へようこそ!まず最初に押さえておきたいのが「教師あり学習」です。このセクションでは、教師あり学習の基本的な定義と、その仕組みについて分かりやすく解説していきます。
教師あり学習の定義
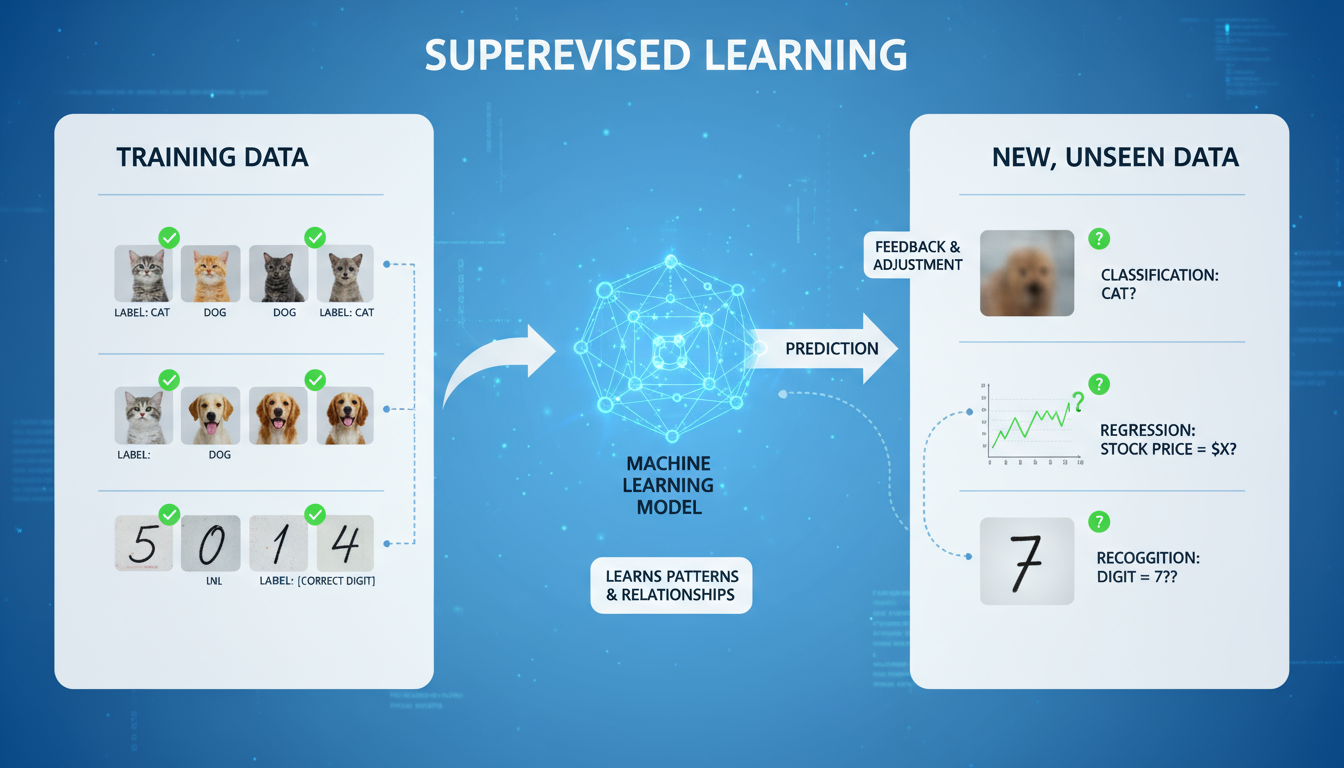
教師あり学習とは、AIや機械学習の手法の一つであり、あらかじめ「正解」が与えられたデータ(これを「教師データ」と呼びます)を用いて、モデルに学習させるアプローチです。具体的には、入力データとその入力に対する正しい出力(ラベルやターゲットとも呼ばれます)のペアを大量に用意し、モデルが入力から出力を予測できるように訓練します。例えば、「この画像は猫である(正解)」という情報と画像データをセットで与え、猫の画像を学習させるようなイメージです。この「正解」があることで、モデルは入力データと出力の関係性を学習し、未知のデータに対しても適切な予測や分類を行えるようになります。
教師あり学習の仕組み
教師あり学習のプロセスは、大きく分けて「学習(訓練)」と「予測(推論)」の二段階で構成されます。まず、訓練段階では、用意した教師データ(入力データと正解ラベルのペア)をモデルに与えます。モデルは、入力データと正解ラベルを比較しながら、自身の予測が正解とどれだけ異なっているか(誤差)を計算します。そして、その誤差を小さくするように、モデル内部のパラメータを繰り返し調整していきます。この調整の繰り返しにより、モデルは入力データの特徴と正解ラベルの間の関係性を徐々に学習していきます。例えば、スパムメール検出の場合、大量のメールとそのメールがスパムか否かのラベル(正解)を学習することで、新しいメールが届いた際に、それがスパムである可能性を予測できるようになります。学習が完了したモデルは、未知のデータ(例:新しいメール)が与えられた際に、学習した関係性に基づいて最も確からしい予測(例:スパムである、または正常なメールである)を出力します。この「正解」を元に学習を進めることから、「教師あり」学習と呼ばれています。
教師あり学習のメリットとデメリット
ここでは、教師あり学習が持つ利点と、一方で考慮すべき欠点について解説します。これにより、読者は教師あり学習を適用する際の判断材料を得られます。
メリット
教師あり学習は、その特性から多くのメリットを持っています。まず、最も大きな利点として、高い予測精度が挙げられます。正解ラベルが付与されたデータを用いて学習するため、モデルは入力データと出力の関係性を正確に捉えやすく、未知のデータに対しても高い精度で予測や分類を行うことが可能です。
次に、明確な目的設定が容易である点もメリットです。例えば、「このメールはスパムか否か」や「住宅価格はいくらか」といった具体的な問題に対して、直接的にモデルを構築できます。これにより、開発者は目指すべきゴールを明確にしやすく、学習プロセスも管理しやすくなります。
さらに、多くの場合、学習済みのモデルは解釈しやすいという特徴があります。特に決定木や線形回帰などのアルゴリズムは、どのような特徴量が予測に寄与しているかを理解しやすいため、ビジネス上の意思決定や原因分析に役立ちます。これにより、AIのブラックボックス化を防ぎ、信頼性を高めることができます。
デメリット
一方で、教師あり学習にはいくつかのデメリットや注意すべき点も存在します。最も重要な課題の一つは、教師データの準備コストです。質の高い、十分な量の教師データを用意するには、専門知識を持つ人材によるラベル付け作業が必要となり、時間とコストがかかる場合があります。特に、画像認識や自然言語処理など、複雑なタスクではこの傾向が顕著です。
また、ラベル付けの難しさも課題となります。データによっては、正解ラベルを定義することが技術的に困難であったり、主観が入りやすかったりする場合があります。例えば、感情分析において「ポジティブ」「ネガティブ」の境界線が曖昧なケースなどが考えられます。
さらに、過学習(オーバーフィッティング)のリスクも考慮しなければなりません。モデルが学習データに過剰に適合しすぎると、未知のデータに対する汎化性能が低下します。つまり、学習データでは高い精度を示すものの、実際の運用では期待通りの結果が得られない可能性があります。これを防ぐためには、適切なモデル選択や正則化などのテクニックが必要となります。
教師あり学習の活用事例
教師あり学習は、その名の通り「正解」が与えられたデータを用いて学習を進めるため、具体的な予測や分類タスクに非常に強力な手法です。ここでは、教師あり学習がどのように活用されているのか、代表的な「分類問題」と「回帰問題」の事例を、ビジネスシーンへの応用例と共にご紹介します。
分類問題の活用事例
分類問題とは、データをあらかじめ定義されたいくつかのカテゴリ(クラス)のいずれかに分類するタスクです。例えば、あるメールが「スパム」か「通常のメール」かを判断したり、画像に写っているのが「犬」なのか「猫」なのかを識別したりする際に用いられます。
具体的な活用事例:
- スパムメール検出: 受信したメールの内容や送信元情報などを分析し、「スパム」か「非スパム」かを自動で分類します。これにより、迷惑メールフォルダを整理し、重要なメールを見逃すリスクを減らすことができます。
- 画像認識: 画像データから、写っている物体が何であるかを識別します。例えば、医療画像から病変の有無を判定したり、製造ラインで製品の良否を判定したりするのに利用されます。
- 顧客の離反予測: 顧客の購買履歴、ウェブサイトでの行動パターン、問い合わせ履歴などのデータから、その顧客が将来的にサービスを解約するかどうかを予測します。これにより、解約の兆候が見られる顧客に対して、個別のフォローアップや特典提供を行い、解約率の低下を目指します。
ビジネスへの応用例(金融での不正検知):
クレジットカードの利用履歴や取引パターンを分析し、不正利用の可能性が高い取引をリアルタイムで検知します。これにより、不正利用による損失を最小限に抑え、顧客の信頼を守ることができます。
教師なし学習、強化学習との違い
教師あり学習の理解を深めるためには、他の主要な機械学習手法である教師なし学習や強化学習との違いを明確にすることが不可欠です。それぞれの学習方法がどのようなデータを使用し、どのような目的で学習を進めるのかを比較することで、教師あり学習の特性がより一層際立ちます。
教師あり学習・教師なし学習・強化学習の比較
| 特徴 | 教師あり学習 | 教師なし学習 | 強化学習 |
|---|---|---|---|
| 学習データ | 入力データと正解ラベルのペア(教師データ) | 入力データのみ(ラベルなし) | 環境との相互作用(状態、行動、報酬) |
| 学習の目的 | 入力データから正解ラベルを予測するモデルの構築 | データに潜む構造やパターンを発見する | 環境内で累積報酬を最大化する行動方策の獲得 |
| 主なタスク | 分類、回帰 | クラスタリング、次元削減、異常検知 | ゲームAI、ロボット制御、推薦システム(一部) |
| フィードバック | 正解ラベルとの誤差 | 明示的なフィードバックなし | 報酬(成功)または罰(失敗) |
教師なし学習は、あらかじめ正解が与えられていないデータから、データそのものの構造や特徴を発見しようとするアプローチです。例えば、顧客データを分析して似た者同士のグループに分ける(クラスタリング)といったタスクに用いられます。教師あり学習のように「これが正解」という情報がないため、データの中から意味のあるパターンを見つけ出すことが中心となります。
一方、強化学習は、エージェント(学習主体)が環境の中で試行錯誤を繰り返しながら、より多くの報酬(成功)を得られるような行動を学習していく手法です。例えば、ゲームのAIがプレイを繰り返して高得点を目指したり、ロボットが歩き方を学習したりする際に使われます。ここでも正解ラベルはありませんが、行動の結果として得られる「報酬」という形でフィードバックが得られる点が、教師なし学習とは異なります。
教師あり学習で用いられる主なアルゴリズム
教師あり学習には、目的に応じて様々なアルゴリズムが存在します。ここでは、代表的なものをいくつか紹介し、それぞれの特徴と得意とする問題の種類について解説します。
線形回帰 (Linear Regression)
線形回帰は、説明変数と目的変数の間に線形関係があると仮定し、その関係性を表す直線(または超平面)を求めるアルゴリズムです。最も基本的な回帰アルゴリズムの一つであり、連続値の予測に用いられます。
ロジスティック回帰 (Logistic Regression)
ロジスティック回帰は、線形回帰を応用し、目的変数がカテゴリカルな値(例: 0か1、YesかNo)である場合に、その確率を予測するために使用されます。主に二値分類問題に用いられます。
決定木 (Decision Tree)
決定木は、データをツリー構造で分割していくことで、分類や回帰を行うアルゴリズムです。各ノードで特徴量に基づいた質問を行い、葉ノードで最終的な予測値を得ます。解釈性が高いのが特徴です。
サポートベクターマシン (Support Vector Machine: SVM)
SVMは、データを高次元空間に写像し、クラス間のマージン(境界線からの距離)を最大化するように境界線を見つけるアルゴリズムです。分類問題に強力で、特に非線形なデータに対しても有効です。
ニューラルネットワーク (Neural Network)
ニューラルネットワークは、人間の脳神経回路を模倣したモデルで、複数の層(入力層、隠れ層、出力層)を持つ構造をしています。複雑なパターン認識や、画像認識、自然言語処理などの分野で高い性能を発揮します。ディープラーニングの基礎となる技術です。
その他のアルゴリズム
上記以外にも、ランダムフォレスト、勾配ブースティング、k近傍法 (k-NN) など、様々なアルゴリズムが存在します。これらのアルゴリズムは、それぞれ異なる特性や得意分野を持っているため、問題の性質やデータの特性に応じて最適なものを選択することが重要です。
教師あり学習を始めるためのステップ
ここでは、教師あり学習を実際に学び、実践していくための具体的なステップを解説します。データ収集からモデルの評価・改善まで、一連の流れを理解することで、スムーズに学習を進めることができるでしょう。
教師あり学習を始めるにあたっては、一般的に以下のステップを踏みます。
- 問題定義と目標設定: まず、解決したいビジネス課題や研究テーマを明確にし、教師あり学習で何を達成したいのか、具体的な目標を設定します。例えば、「顧客の購買確率を予測したい」「画像に写っている物体を特定したい」といった形です。
- データ収集: 目標達成に必要なデータを収集します。教師あり学習では、入力データ(特徴量)とそれに対応する正解ラベル(ターゲット変数)のペアが必要です。例えば、顧客の購買履歴データと、実際に購入したかどうかを示すラベルなどです。
- データ前処理: 収集したデータは、そのままでは利用できないことが多いため、クリーニングや整形を行います。欠損値の処理、外れ値の検出・除去、カテゴリ変数の数値化(エンコーディング)、特徴量のスケーリング(正規化・標準化)などが含まれます。この工程は、モデルの性能に大きく影響するため非常に重要です。
- モデル選択: 解きたい問題の種類(分類問題か回帰問題かなど)やデータの特性に合わせて、適切な機械学習アルゴリズムを選択します。ロジスティック回帰、サポートベクターマシン(SVM)、決定木、ランダムフォレスト、ニューラルネットワークなど、様々なアルゴリズムが存在します。
- 学習(トレーニング): 選択したアルゴリズムに、前処理済みの学習用データセットを与えて学習させます。このプロセスで、モデルはデータの特徴と正解ラベルの関係性を学習し、パラメータを調整していきます。
- 評価: 学習済みのモデルが、未知のデータに対してどの程度の精度で予測できるかを評価します。テスト用データセットを用いて、精度(Accuracy)、適合率(Precision)、再現率(Recall)、F1スコア、平均二乗誤差(MSE)などの評価指標で性能を測定します。
- ハイパーパラメータチューニング: モデルの性能が十分でない場合、アルゴリズムのハイパーパラメータ(学習プロセスを制御する設定値)を調整し、モデルの性能向上を目指します。グリッドサーチやランダムサーチなどの手法が用いられます。
- デプロイとモニタリング: 最適なモデルが得られたら、実際のシステムやアプリケーションに組み込んで利用(デプロイ)します。運用開始後も、モデルの性能を継続的に監視し、必要に応じて再学習や改善を行います。
これらのステップは、必ずしも直線的に進むわけではなく、評価の結果を受けて前のステップに戻ってデータを再処理したり、別のモデルを試したりするなど、反復的に行われることが一般的です。Pythonのscikit-learnのようなライブラリを利用すると、これらのステップの多くを効率的に実行できます。
教師あり学習の注意点と課題
教師あり学習は強力な手法ですが、その適用にはいくつかの注意点と課題が存在します。これらを理解し、適切に対処することで、より効果的かつ倫理的なAI活用が可能になります。
データバイアス
教師あり学習の性能は、学習に用いる教師データの質に大きく依存します。もし教師データに偏り(バイアス)が含まれている場合、モデルはそのバイアスを学習してしまい、特定の属性(性別、人種など)に対して不公平または不正確な予測を行う可能性があります。例えば、過去の採用データに性別による偏りがあれば、それを学習したモデルも同様の偏りを持つ可能性があります。このバイアスを軽減するためには、データの収集段階での注意や、バイアス検出・緩和アルゴリズムの適用が重要です。
説明責任 (Explainability)
特にディープラーニングのような複雑なモデルでは、「なぜそのような予測結果になったのか」を人間が理解することが難しい場合があります。これは「ブラックボックス問題」とも呼ばれ、金融や医療など、判断根拠の説明が求められる分野での利用において大きな課題となります。近年では、Explainable AI (XAI) の研究が進み、モデルの判断根拠を可視化・説明する技術が開発されていますが、まだ発展途上の分野です。
計算リソースと時間
大規模なデータセットや複雑なモデルを用いた教師あり学習には、膨大な計算リソース(高性能なCPU/GPU)と時間が必要です。モデルの学習やチューニングには、試行錯誤が伴うため、特に初期段階ではコストがかかることがあります。クラウドコンピューティングの活用や、より効率的なアルゴリズムの選択が、この課題への対応策となり得ます。
過学習 (Overfitting)
モデルが学習データに過剰に適合しすぎると、未知のデータに対する予測精度が低下する「過学習」が発生します。これは、モデルがデータに含まれるノイズまで学習してしまうことが原因です。過学習を防ぐためには、学習データの量を増やす、モデルの複雑さを調整する(正則化)、交差検証を行うなどの手法が用いられます。
教師データの取得とアノテーションコスト
教師あり学習の最大のボトルネックの一つは、質の高い教師データを大量に準備することです。データ収集だけでなく、各データに正解ラベルを付与する「アノテーション」作業は、専門知識を要する場合も多く、時間とコストがかかります。このコストを削減するために、自己教師あり学習や、少量のラベル付きデータで学習する手法(Few-shot Learning)などが研究されています。
倫理的な考慮
教師あり学習モデルの利用は、プライバシー侵害、差別、誤情報の拡散など、様々な倫理的な問題を引き起こす可能性があります。開発者や利用者は、これらのリスクを十分に理解し、倫理的なガイドラインを遵守しながら、責任あるAI活用を心がける必要があります。
まとめ
ここまで、教師あり学習の定義、仕組み、メリット・デメリット、そして具体的な活用事例について解説してきました。教師あり学習は、正解ラベルが付与されたデータを用いて、未知のデータに対する予測や分類を行う強力な手法です。分類問題や回帰問題など、様々な課題に応用されています。
また、教師なし学習や強化学習といった他の機械学習手法との違いも理解いただけたかと思います。それぞれの学習手法には得意な領域があり、解決したい課題に応じて適切な手法を選択することが重要です。
教師あり学習は、AI技術の中核をなすものであり、その理解はAIの世界をさらに深く探求するための第一歩となります。今回学んだ知識を基に、ぜひご自身の興味のある分野での活用や、さらなる学習へと進んでみてください。AIの可能性は無限大です。
